|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

|
| We present CoGS, a novel method for the style-conditioned, sketch-driven synthesis of images. CoGS enables exploration of diverse appearance possibilities for a given sketched object, enabling decoupled control over the structure and the appearance of the output. Coarse-grained control over object structure and appearance are enabled via an input sketch and an exemplar "style" conditioning image to a transformer-based sketch and style encoder to generate a discrete codebook representation. We map the codebook representation into a metric space, enabling fine-grained control over selection and interpolation between multiple synthesis options before generating the image via a vector quantized GAN (VQGAN) decoder. Our framework thereby unifies search and synthesis tasks, in that a sketch and style pair may be used to run an initial synthesis which may be refined via combination with similar results in a search corpus to produce an image more closely matching the user's intent. We show that our model, trained on the 125 object classes of our newly created Pseudosketches dataset, is capable of producing a diverse gamut of semantic content and appearance styles. |
<
Code
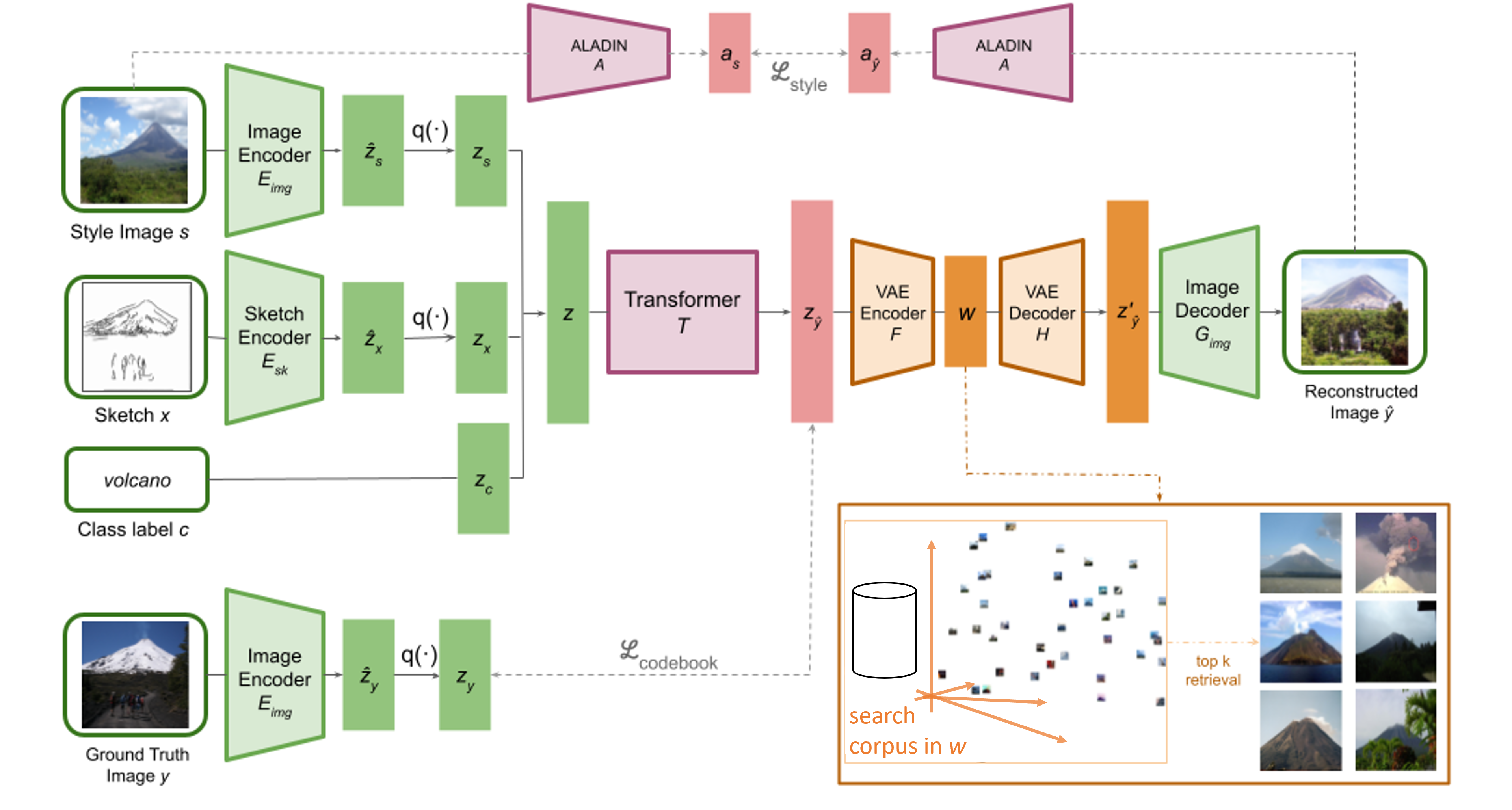 |
| Illustration of the full CoGS pipeline. We use VQGANs (shown in green) to learn two codebooks, one for sketches and one for images, which are combined with a tokenized representation of a class label. Then, we use a transformer with an auxiliary style loss (shown in red) to learn to composite the inputs into a predicted codebook, which can be subsequently decoded by the image VQGAN decoder to synthesize an image. The input structure and style images offer coarse-grained control over the synthesis. Finally, we use a VAE (shown in orange) to map the codebook to and from a latent space that enables fine-grained refinement of the output image via retrieval or interpolation of results from a search corpus. |
Pseudosketches Dataset
 |
| Stages in the creation of the Pseudosketches dataset. Given an input image, we generate its saliency mask, blur the non-salient regions, and extract the edgemap of the masked image using L2T. Without the saliency mask blurring, we would retain background details not present in hand-drawn sketches. |
 |
C. Ham*, G. C. Tarres*, T. Bui, J. Hays, Z. Lin, J. Collomosse. CoGS: Controllable Generation and Search from Sketch and Style ECCV, 2022. (hosted on ArXiv) |
This template was originally made by Phillip Isola and Richard Zhang for a colorful ECCV project; the code can be found here.