
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| tl;dr We propose personalized residuals, a small set of low-rank residuals, for efficient personalization of diffusion models. We also introduce localized attention-guided (LAG) sampling, which combines the newly learned concept with the existing generative capacity of the base model. |
|
|
| We present personalized residuals and localized attention-guided sampling for efficient concept-driven generation using text-to-image diffusion models. Our method first represents concepts by freezing the weights of a pretrained text-conditioned diffusion model and learning low-rank residuals for a small subset of the model's layers. The residual-based approach then directly enables application of our proposed sampling technique, which applies the learned residuals only in areas where the concept is localized via cross-attention and applies the original diffusion weights in all other regions. Localized sampling therefore combines the learned identity of the concept with the existing generative prior of the underlying diffusion model. We show that personalized residuals effectively capture the identity of a concept in ~3 minutes on a single GPU without the use of regularization images and with fewer parameters than previous models, and localized sampling allows using the original model as strong prior for large parts of the image. |
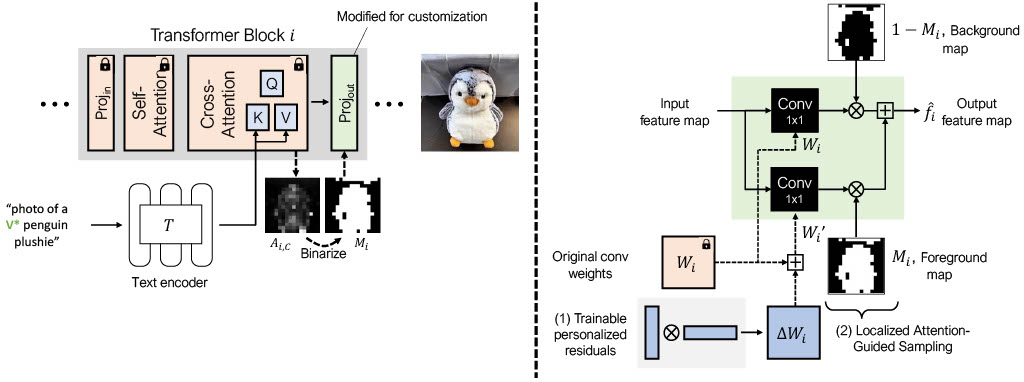 |
| (1) Personalized residuals: We learn low-rank residuals for the output projection layer within each transformer block in the diffusion model. The residuals contain relatively few parameters, are fast to train, and do not require any regularization images during training. (2) Localized attention-guided sampling: We optionally apply the personalized residuals only in the areas that the cross-attention layers have localized the concept via predicted attention maps. Thus, we can combine the newly learned concept with the original generative prior of the base diffusion model within a single image. |
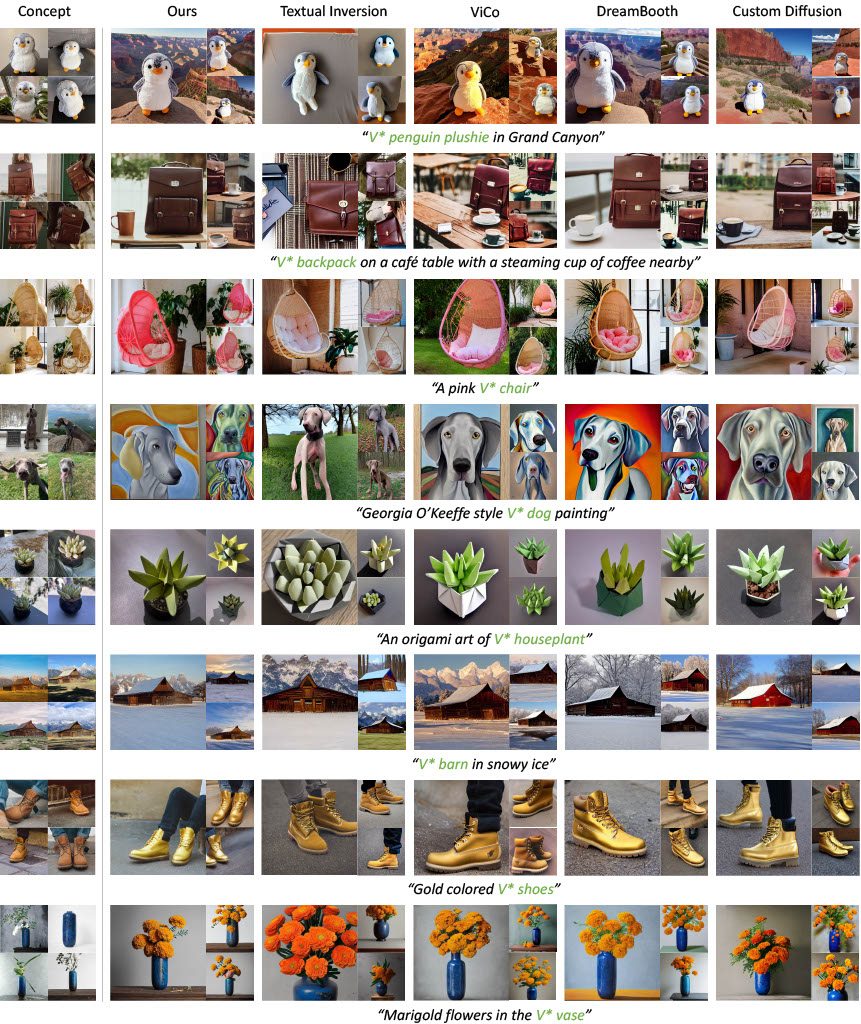 |
| We compare our proposed approach against several baselines. |
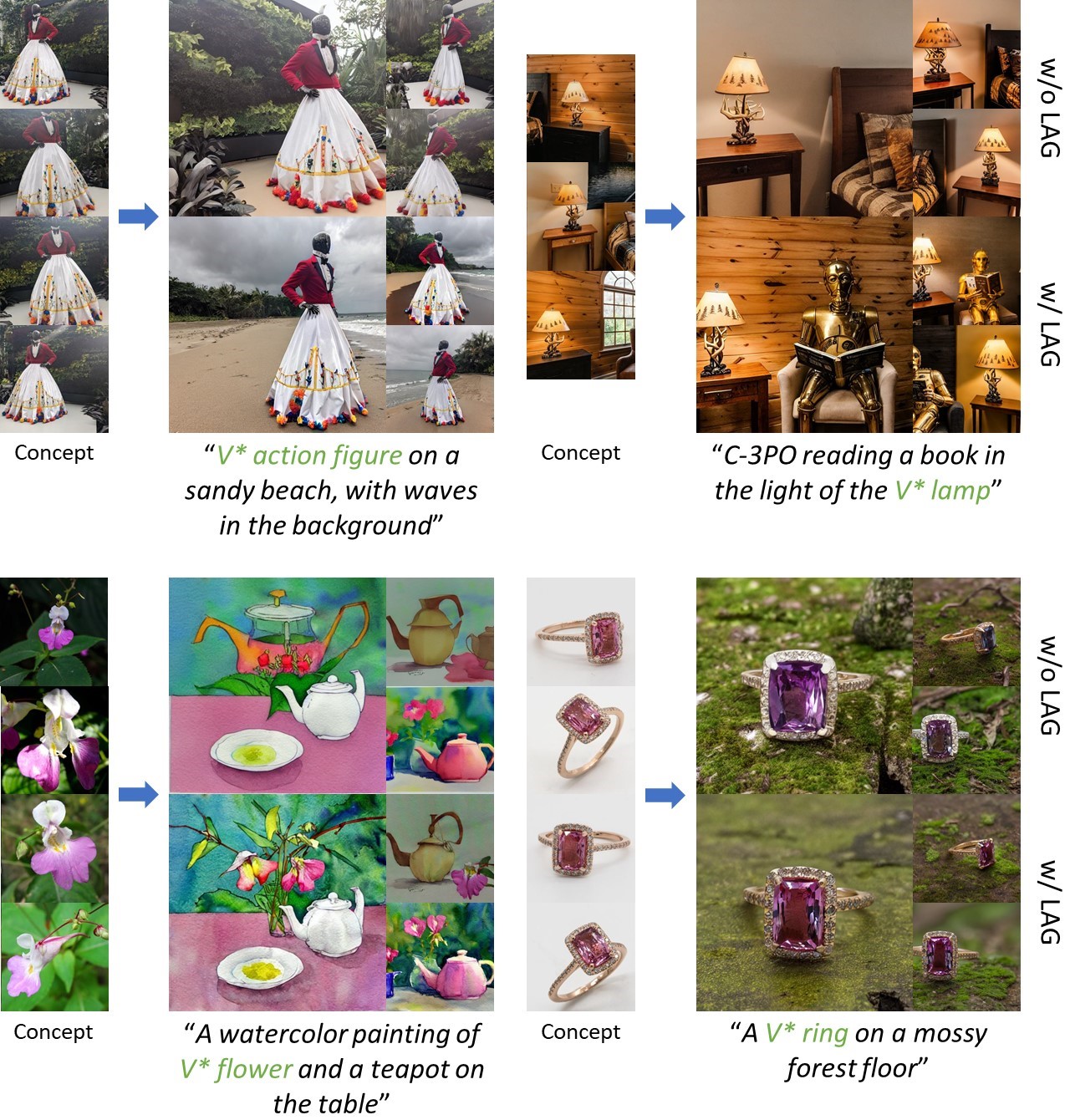 |
| Examples where LAG sampling produces results that are better aligned with the concept and prompt than normal DDIM sampling. |
 |
| Examples where normal sampling produces results that are better aligned with the concept and prompt. |
 |
C. Ham, M. Fisher, J. Hays, N. Kolkin, Y. Liu, R. Zhang, T. Hinz. Personalized Residuals for Concept-Driven Text-to-Image Generation CVPR, 2024. (hosted on ArXiv) |
This template was originally made by Phillip Isola and Richard Zhang for a colorful ECCV project; the code can be found here.